
Basic Natural Language Processing
Natural language processing provides morphologic, syntactic, and semantic tools to help transform stored text from raw data (e.g., dictated text) to useful information (e.g., a standardized diagnostic classification). Morphologic tools look at stored text as a sequence of linguistic units without regard to context or meaning. Syntactic tools provide grammar-related information about the text. Semantic tools, such as thesauri and ontologies, provide information about the meaning and sense of words. Taken together, these NLP tools can be used to resolve issues brought about by ambiguity, negation, and synonymy found in stored text. NLP has been successfully applied to stored text in a wide range of applications, including machine translation, question answering, information retrieval, document summarization, and author identification.
Low-Level Natural Language Processing
Low-level NLP tasks include:
1. Tokenization: identifying individual tokens (word, punctuation) within a sentence. A lexer plays a core role for this task.
2. Sentence boundary detection: Once tokenized by a lexer, we need to determine the scope of each sentence. Tokens, such as abbreviations and titles (e.g., ‘hr.,’ ‘Ms.’), may contain characters typically used as token boundaries which complicates this task. Lists, as well as items with hyphens or slashes may also complicate sentence boundary detection..
3. Part-of-speech assignment to individual words (‘POS tagging’): in English, homographs (‘set’) and gerunds (verbs ending in ‘ing’ that are used as nouns) complicate this task.
4. Morphological decomposition: A useful sub-task is stemming - conversion of a word to a root by removing suffixes, thus conflating variations of a given word. For example, extracted and extraction would both stem to extract. Spell-checking applications and preparation of text for indexing/searching may employ morphological analysis and decomposition.
5. Shallow parsing (chunking): identifying phrases from constituent part-of-speech tagged tokens. For example, a noun phrase may comprise an adjective sequence followed by a noun (e.g., White House).
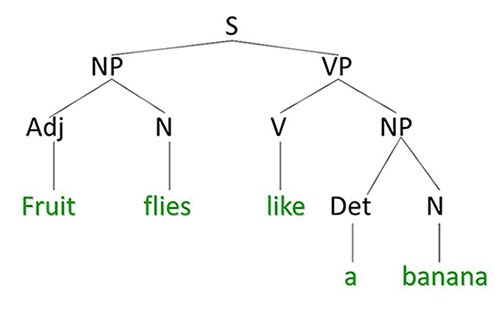
Ambiguity
Ambiguity is the inability to discern the sense of a polysemous word (i.e., a word with two or more meanings) in a specific context. Word sense disambiguation (WSD) attempts to determine the correct sense of a word. Using a Part of Speech tagger (i.e., diagraming the sentence) by itself can help to disambiguate a word based upon the part of speech (e.g., , pool is a noun in They swam in the pool. but a verb in They decided to pool their resources). However, the tagger can not disambiguate when the various senses have the same part of speech. For example, is Monty Hall the name of a person, or the name of an auditorium?
- The boy hit the girl with the bat.


Automated Classification
The task of automated classification entails the training, or the creation, of a classifier that assigns class labels to instances in the data. Automated classification forms the basis for systems that can be used for diverse purposes including spam filtering, authorship attribution, web page classification, and the assignment of medical billing codes to patient records. Systems have been based on hand-crafted rules, on machine learning algorithms, and on a combination of both approaches. Hand-crafted rules and machine learning algorithms each have their own strengths and weaknesses. Systems based on hand-crafted rules benefit from expert knowledge of the domain but require considerable effort to retrain. However, while machine learning systems can usually be retrained with minimal effort, they may not perform as well as hand-crafted rule-based systems
Automated vs Manual Classification
Comparing automated classification with manual classification performed by humans we see that manual classification is typically based upon Aristotle’s hierarchical theory of categories that brings items with common characteristics together into the same grouping. This approach has sufficed when dealing with a relatively small number of items that could be placed into relatively broad and well-defined categories (e.g., books into U.S. Library of Congress Subject Headings). On the one hand, manual classification can be labor intensive, costly, and can suffer from issues of consistency in class assignments. Automated classification, on the other hand, can reduce the labor and labor related costs associated with manual classification, while at the same time can provide consistent class assignments.
Project Description
A significant portion of Special Education Student (SES) data is recorded in narrative form. While often computerized, the narrative is simply stored on the computer as free text, which does not facilitate access to the wealth of this information. Merely collecting data is not enough to lead to improved student outcomes or to effective monitoring. We can compare this to the medical field, where patient records also contain a significant amount of narrative data. However, the medical field has developed and successfully implemented Natural Language Processing (NLP) tools to leverage stored free text from the narrative of patient records in order to help improve patient outcomes.
The purpose of this project is to develop a system that employs tools created for the narrative of patient records and apply and adapt those tools to the narrative of SES records. While this project will not lead to the development of new student interventions or assessments, we believe that the application of these NLP tools to the narrative of Special Education student records would make SES data more accessible and interpretable, allowing districts to make the best decisions for their students, thereby resulting in the improvement of student education outcomes.
The project will solicit Special Education students who live in a four county region in upstate New York to participate in the study. The students will come from a mix of urban (high poverty, small city), suburban, and rural (northern Appalachian region) school districts. The students will be between the ages of 6 and 21, and will come from a mix of those in a public school setting and those attending a stand-alone regional Special Education facility. The sample will consist of the records of the first 200 students who return the parental consent and student assent forms.
The research design of the project consists of two phases. Phase I will evaluate the effectiveness of various NLP tools when applied to existing SES narrative data. These tools will range from part-of-speech assignment of individual words to topic detection and automated classification of the text. The goal will be to transform the narrative stored as free text from raw data into useful information. The results will be evaluated using Precision, Recall, and F‑measure, metrics commonly used to evaluate NLP systems.
Phase II will develop and evaluate a system that will take the SES narrative data, looking back over a student’s career (to date), and will create a temporal oriented catalog of changes that were introduced to the student. This information, when combined with the student’s quantitative data, should allow the district to see the changes that took place over the long term as well as the actual impact of those changes. The system will initially consist of two applications. The first application will detect cases where a given year’s IEP team prescribes the same change agent year after year regardless of effect. The second application will align the temporal oriented catalog of changes with the student’s quantitative data, enabling a better understanding of the effects of one change, or multiple changes, to a student’s performance over multiple years. The results of this phase will be evaluated using DeLone & McLean’s (2002, 2003) Updated Information Systems Success Model, which has been validated in numerous Information System studies. The system will be evaluated, at both an individual and organizational level, by analyzing the following key measures: System Quality (e.g., usability, adaptability), Information Quality (e.g., completeness, relevance), Use (both self-reported and actual), User Satisfaction, and Net Benefits (capturing both positive and negative impacts). The results will be tested using Chi Square and factor loading analysis.
Chi Square is a statistical test commonly used to compare observed data with data we would expect to obtain according to a specific hypothesis.
Tip: Hover over unfamiliar terms for their definitions
Definitions provided by the following sources:"Token", "F-Measure", "Recall"- Provided by Dr. Ira Goldstein. "Precision", "Polysemy", "Algorithm", "Morphology"- from www.oxforddictionaries.com. "Lexer"- adapted from http://savage.net.au/Ron/html/graphviz2.marpa/Lexing.and.Parsing.Overview.html#The_Lexer%27s_Job_Description. "Chi-square"- from http://www2.lv.psu.edu./jxm57/irp/chisquar.html. "Factor Analysis"- from http://www.ats.ucla.edu/stat/seminars/muthen_08/part2.pd
Primary page content provided by Dr. Ira Goldstein.
Click here for parental consent form